Всё, что нужно знать об обучении агентов
простыми словами

Ещё недавно обучение с подкреплением для LLM выглядело так: модели показывают промт, она выдаёт один ответ, и этот ответ «оценивают» — людьми или автоматическими метриками. Это отлично работает для подстройки стиля, вежливости и следования инструкциям, но почти не похоже на реальную жизнь, где нужно действовать шаг за шагом, ошибаться, исправляться, искать информацию и помнить, что было минуту назад.
Авторы обзора “The Landscape of Agentic Reinforcement Learning for LLMs: A Survey” предлагают смотреть на LLM иначе: как на агента, который живёт в среде и принимает решения на длинной дистанции. Это и есть сдвиг к agentic reinforcement learning (agentic RL) — когда обучение с подкреплением используется не только для «хорошего ответа», а для устойчивого поведения в динамических условиях: с инструментами, памятью, планированием и частичной наблюдаемостью.

В чём проблема: одношаговая логика против длинных задач
Классический посттренинг с RL часто можно представить как вырожденный случай: есть один шаг, один ответ, и всё закончено. В обзоре это формализуют так: вместо одношагового процесса авторы переводят диалог в язык POMDP — задач, где агент видит не весь мир, а лишь кусочек наблюдений, и должен действовать последовательно, чтобы накопить информацию и добиться цели.
В агентных сценариях действие — это не только текст. Это ещё и вызов инструментов (поиск, код, браузер, API), перемещения в среде (например, в игре или GUI), обновление памяти, выбор стратегии рассуждений. И самое сложное — награда часто приходит позднее за то, что задача действительно решена.

Две «карты местности»
Работа по сути — большой навигатор по сотням разрозненных исследований. Авторы синтезируют более 500 работ и предлагают два направления.
Первое — способности агента. Здесь обсуждаются планирование, использование инструментов, память, рассуждения, самоулучшение и восприятие. Важно, что agentic RL рассматривает эти компоненты не как прикрученные сверху скрипты, а как части поведения, которые можно и нужно «воспитывать» наградой. То есть RL превращает статические эвристики в адаптивные привычки.
Второе — классы задач: исследовательские агенты для поиска, кодинг и software engineering, математика, навигация по интерфейсам, визуальные задачи, embodied-сценарии и мультиагентные системы. Такой разрез помогает понять, почему одни подходы работают, а другие тяжело масштабируются в веб-среде.
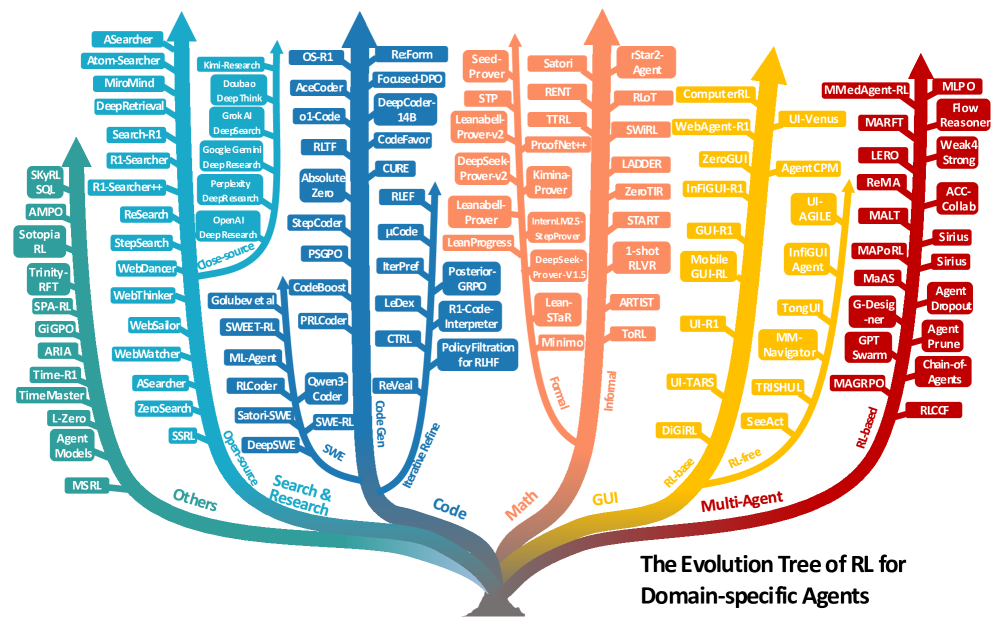
Что именно делает RL «агентным»
Один из самых полезных тезисов обзора: RL начинает играть главную роль там, где нужно научиться выбирать — когда планировать глубже, когда вызвать инструмент, что записать в память, как корректировать себя после ошибки. В промт-инженеринге SFT можно имитировать правильные паттерны, но трудно добиться устойчивости к неожиданностям. RL же привязывает поведение к исходу: получилось — усиливаем; провалилось — перестраиваем стратегию.
Чаще всего это видно в использовании инструментов. В ранних архитектурах модель просто повторяла шаблон Thought → Action → Observation. Agentic RL двигает поле к tool-integrated reasoning, где инструмент не «придаток», а часть рассуждения и принятия решений, причём на длинных задачах, с проблемой credit assignment: как не наказать полезное исследование, которое не дало результат сразу.

Что получается на выходе: заметные успехи и честные ограничения
Обзор показывает, что agentic RL особенно силён там, где есть проверяемый результат: код (юнит-тесты), формальные проверки, исполняемые пайплайны, верифицируемые метрики в vision (например, IoU). Поэтому именно в коде/SWE-сценариях мы видим быстрый прогресс: RL учит модель не только писать код, но и чинить его итеративно, вызывать интерпретатор вовремя, выдерживать длинные траектории правок.
Но авторы не скрывают и фундаментальные сложности. Главная — всё тот же temporal credit assignment в реальных средах: награда редкая, путь длинный, а ошибки могут быть «шумом среды», а не глупостью агента. Добавьте сюда стоимость инструментов (веб-поиск, браузинг), нестабильность источников и риск обучиться обходным трюкам вместо сути. Поэтому в будущих направлениях явно читается запрос на более устойчивые протоколы оценки, аккуратные промежуточные сигналы и масштабируемые среды.
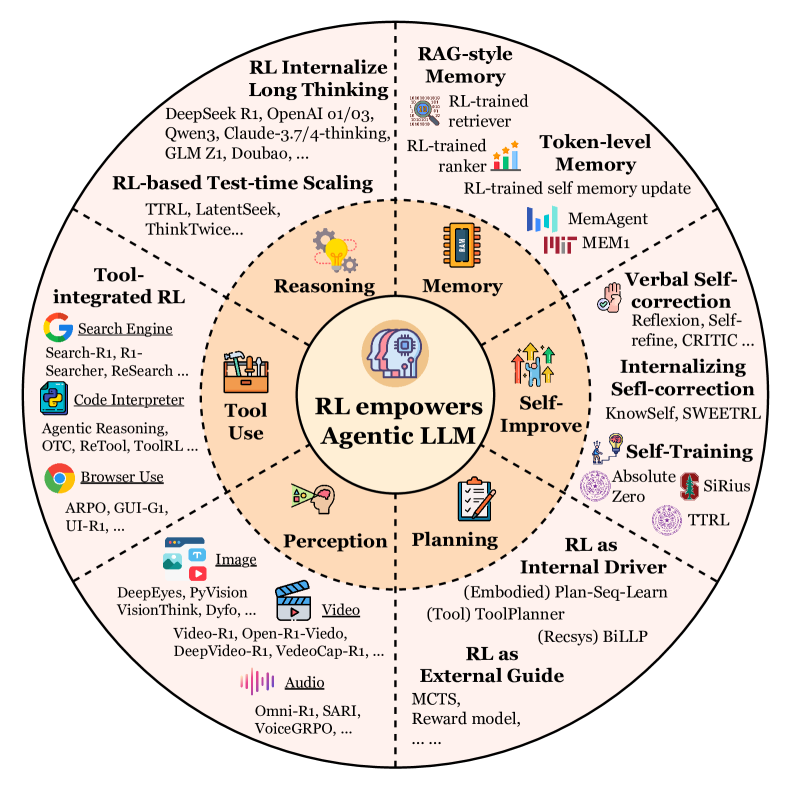
Главное впечатление
Этот обзор показывает, что agentic RL — это по сути воспитание поведение агентов. Когда LLM становится агентом, важнее всего умение спланировать цель и добраться до результата, проверять себя, пользоваться инструментами, помнить контекст и адаптироваться. И именно RL, по мнению авторов, превращает все эти элементы в обучаемую систему.