Теория разума для ИИ:
что происходит, когда агенты начинают «догадываться» о намерениях друг друга

Про мультиагентные системы на базе LLM часто говорят, что это команда агентов, которая сама договаривается, планирует и разруливает сложные задачи. На практике всё менее романтично: как только агентов становится несколько, у них появляется общая проблема — не только что делать, но и как правильно понять друг друга. Один «уверенно предполагает», другой «точно знает», третий молчит в общий чат — и команда разваливается на несогласованные действия.
Авторы работы Evaluating Theory of Mind and Internal Beliefs in LLM-Based Multi-Agent Systems разбирают важный вопрос: если добавить агентам более «человеческие» когнитивные механизмы — умение прикидывать намерения других (Theory of Mind, ToM) и внутренние убеждения в стиле BDI (belief–desire–intention), — станет ли координация лучше? И что будет, если эти убеждения ещё и проверять формальной логикой, чтобы агент не действовал на основе противоречий?

Город, который нужно спасать, и агенты, которые (иногда) мешают друг другу
Чтобы измерять «командный интеллект» не на абстрактных диалогах, исследователи сделали симуляцию: есть город из четырёх районов. Три агента отвечают каждый за свой ресурс — еду, медицину и безопасность. Ресурсы в районах постоянно убывают, и если где-то чего-то не хватает, здоровье района падает. У агентов ограничения по перемещению и по объёму того, что можно нести. Побеждает команда, которая удержит среднее здоровье районов как можно выше.
Здесь хорошо видно, что мультиагентная система — это не «три независимых решения», а непрерывная синхронизация: кому куда ехать, кто что уже везёт, какой район сейчас критичнее. И главное — насколько можно доверять тому, что другой агент действительно сделает обещанное.

Как устроено «мышление» агента: ToM, внутренние убеждения и проверка логикой
Архитектура в статье строится вокруг двух уровней памяти. Есть shared memory — общее пространство, куда агенты пишут сообщения о наблюдениях и планах. А есть private memory — внутренние заметки, которые не публикуются: там агент хранит свою модель мира, предположения о других и черновик следующего действия.
Дальше — самое интересное. Авторы включали и выключали два когнитивных блока, чтобы сравнить эффект:
- ToM заставляет агента явно формулировать ожидания: что, вероятно, сделают другие агенты, какие у них цели, куда они поедут.
- А Internal Beliefs — это попытка собрать наблюдения в более строгую модель мира, пригодную для рассуждений.
Но они пошли дальше: Internal Beliefs прогоняются через Answer Set Programming с решателем Clingo. Если в убеждениях обнаруживается противоречие, агент получает обратную связь и пересобирает рассуждение (до трёх попыток). То есть система не просто просит думать аккуратнее, а формально проверяет, не развалилось ли описание ситуации на несовместимые утверждения.

Разговоры в общем чате и эффект испорченного телефона
Коммуникация устроена последовательно: агенты по очереди читают общий контекст и добавляют своё сообщение. Это реалистично (так часто делают в LLM-оркестраторах), но даёт побочный эффект: если один агент ошибся в прогнозе или сформулировал план мутно, остальные могут построить на этом неверные решения. ToM в такой схеме — палка о двух концах. Он может помочь предугадать действия партнёра, а может усилить уверенность в неверной догадке.

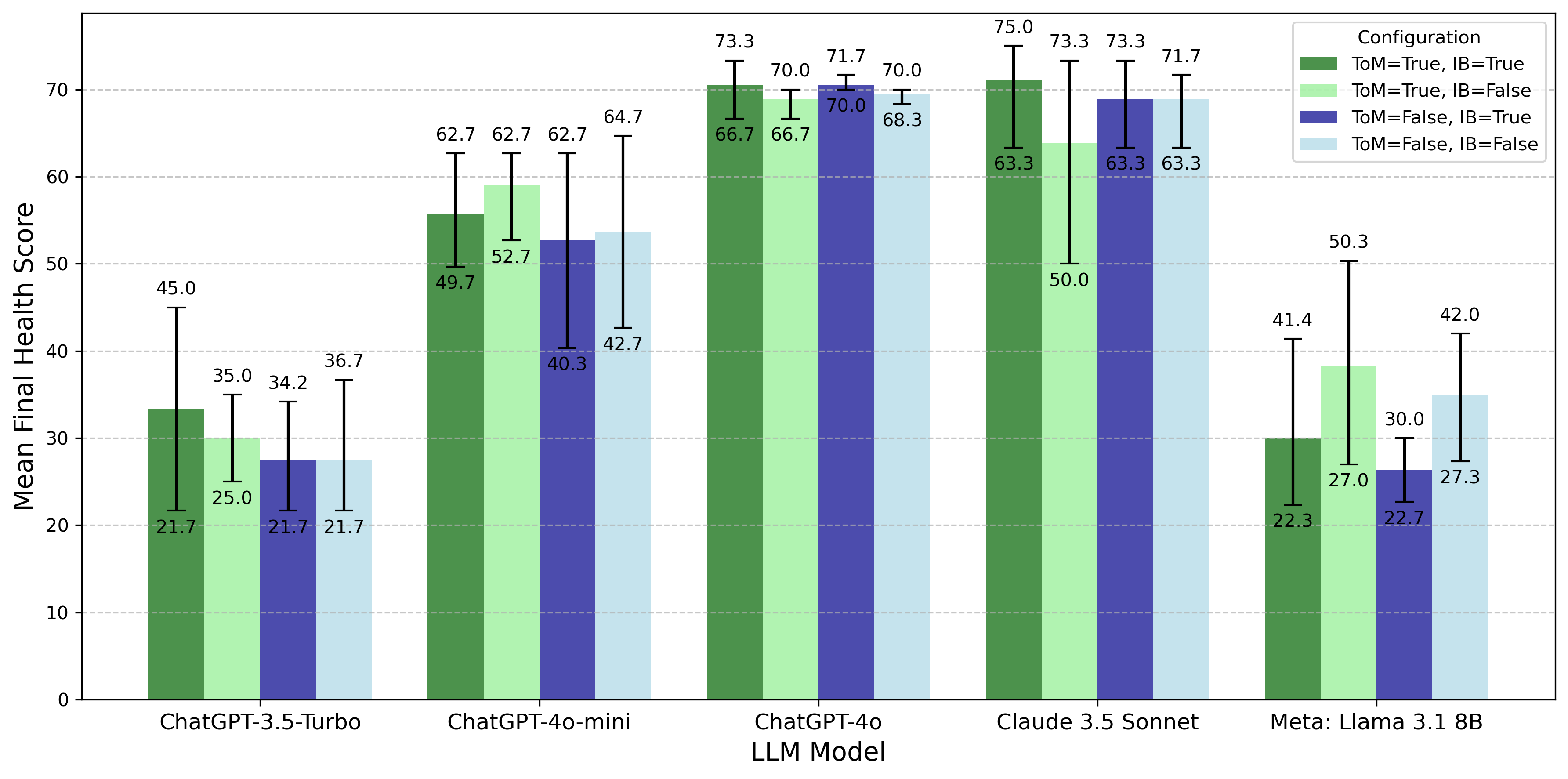
Что получилось на разных LLM: универсального усилителя нет
Эксперименты провели на нескольких LLM: ChatGPT-3.5-Turbo, ChatGPT-4o, ChatGPT-4o-mini, Meta Llama 3.1 8B и Claude 3.5 Sonnet. Для каждой модели сравнили четыре режима: базовый (без ToM и убеждений), только ToM, только Internal Beliefs с логической проверкой и сочетание ToM+IB.
Результат получился неожиданно честным: ToM и внутренние убеждения не дают гарантированного выигрыша. У сильных моделей вроде ChatGPT-4o качество и так высокое и довольно стабильное — включение модулей почти не меняет картину или даёт тонкие сдвиги. У Claude 3.5 Sonnet показатели тоже высокие, но реакция на модули отличается.
У более слабых моделей всё сложнее: иногда добавление ToM помогает, иногда ухудшает — похоже, из‑за когнитивной нагрузки и склонности «додумывать» намерения других. У Meta Llama 3.1 8B, например, режим ToM-only выглядит заметно лучше, чем некоторые другие комбинации, а связка ToM+IB может проседать.
Эту неоднозначность авторы и подчеркивают: в мультиагентной системе важен не сам факт наличия «умных» модулей, а то, насколько конкретная LLM тянет их одновременно и насколько протокол общения не превращает догадки в лавину ошибок.
Что это значит на практике
Главный вывод работы звучит прагматично: если вы строите мультиагентную систему на базе LLM, нельзя просто «прикрутить ToM» или «добавить модель мира» и ждать, что координация взлетит. Эти механизмы могут улучшать работу команды, но могут и мешать — особенно если LLM начинает тратить усилия на сложные рассуждения и при этом ошибается в базовых вещах.
Сильная сторона статьи — демонстрация инженерной реальности: когнитивные надстройки работают только в связке с качеством самой LLM, дизайном памяти, протоколом коммуникации и простыми проверками согласованности. Символическая верификация через Clingo выглядит перспективно как «страховочный ремень», но она тоже не бесплатна: перевод из естественного языка неоднозначен, а вычислительная цена может стать ограничением при масштабировании.