
Когда модели перестанут просто болтать и начнут понимать, что происходит в мире
Последние пару лет ИИ учился очень разным фокусам. Одни модели хорошо продолжают текст. Другие дорисовывают картинку. Третьи пытаются управлять роботом. Но почти все они решают частные задачи: предсказать следующий токен, следующий кадр или следующее действие.
Авторы Orca предлагают посмотреть на проблему иначе. А что, если модели нужно учиться не “следующему слову” и не “следующему пикселю”, а следующему состоянию мира? То есть не просто угадать форму ответа, а внутренне понять: что изменится в сцене, если человек что-то сделал, объект сдвинулся, чашка упала, робот промахнулся и попробовал снова.
Звучит амбициозно. И местами даже слишком. Но работа интересна не громкими обещаниями, а тем, что в ней есть внятная инженерная ставка: собрать общую модель мира, обучить её на видео, событиях и вопросах по видео, а потом проверить, можно ли из одной и той же внутренней репрезентации “считывать” текст, изображения и действия робота.
Если коротко: идея сильная, результаты местами реально впечатляют, особенно для роботов. Но это пока именно ранний шаг, а не готовая универсальная машина понимания мира.
В чём главная идея Orca
Вместо того чтобы строить отдельные модели под текст, видео и роботов, Orca пытается выучить единое скрытое состояние мира. Это внутреннее представление должно отвечать на простой вопрос: “что сейчас происходит и как это может измениться дальше?”
Авторы делают ставку на два режима обучения.
Первый — “бессознательное” обучение. Модель смотрит на непрерывные видео и учится предсказывать, каким будет следующее состояние сцены. Без явных подписей. Просто из потока наблюдений. Так она должна схватывать плотную, естественную динамику: движение объектов, столкновения, перекрытия, инерцию, бытовую физику.
Второй — “сознательное” обучение. Здесь к видео добавляют язык: описания событий, инструкции, вопросы и ответы. Модель учится не просто угадывать ближайшее будущее, а понимать осмысленные переходы: “до” и “после” действия, цель, намерение, причинную связь.

Общая схема Orca: один кодировщик учит скрытое состояние мира, а отдельные лёгкие декодеры превращают его в текст, изображение или действие.
Архитектурно всё устроено довольно аккуратно. Есть кодировщик и декодер. Кодировщик учит это единое внутреннее пространство. Дальше его замораживают, а поверх обучают лёгкие модули чтения в нужную модальность: текст, картинку или управление роботом. Это важный момент. Он нужен, чтобы показать: дело не в том, что под каждую задачу отдельно дообучили большую модель. Дело именно в качестве общего скрытого состояния.
Почему это важно? Потому что в идеале такая схема ближе к тому, как мы сами думаем о мире. У нас нет отдельного “мозга для текста” и отдельного “мозга для захвата ложки”. Есть общая картина происходящего, из которой уже рождаются слова, ожидания и действия.
Как Orca обучали
С данными авторы размахнулись широко. Они собрали набор для “обучения миру”, который включает:
Правда, в этой версии использовали только десятую часть видеоданных. Уже само это говорит, что авторы думают о проекте как о долгой линии, а не о разовом эксперименте.
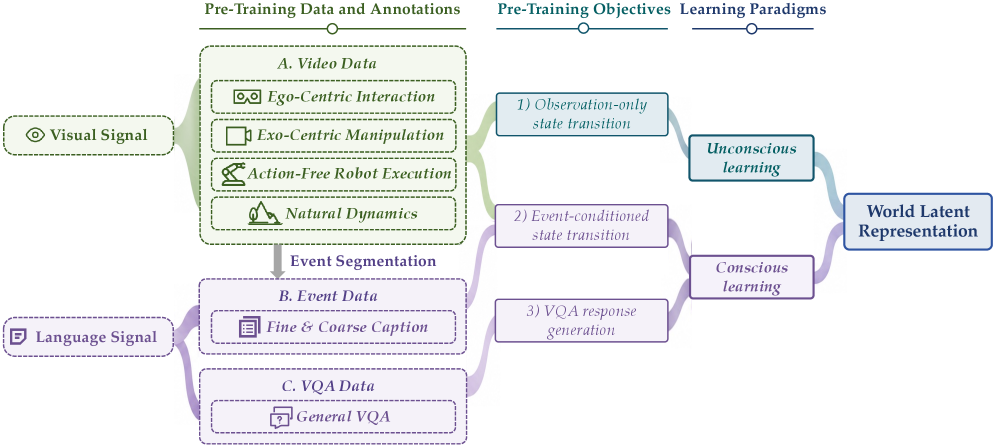
Какие данные использует Orca: непрерывное видео для естественных переходов, события с текстом для осмысленных изменений и VQA для семантики и здравого смысла.
Предобучение строится на трёх задачах.
Первая — предсказать следующее состояние по текущему кадру. Это и есть “бессознательная” часть.
Вторая — предсказать состояние, заданное через событие или инструкцию. Например, модель видит сцену и текстовое условие, которое указывает на предыдущее или следующее значимое событие. Это уже “сознательная” часть.
Третья — отвечать на вопросы по видео. Это нужно, чтобы в скрытое состояние лучше встраивались язык, семантика и бытовой здравый смысл.
Любопытно, что Orca не учат восстанавливать пиксели напрямую. Она предсказывает представление следующего состояния в пространстве визуального кодировщика. То есть ставка не на красивую картинку как таковую, а на смысловую динамику сцены.
После этого кодировщик замораживают. И отдельно обучают три выхода:
Это хороший дизайн для проверки гипотезы. Если при замороженном “ядре” качество в трёх разных задачах растёт, значит внутренняя репрезентация и правда несёт полезную информацию о мире.
Что получилось: главный тезис работы подтверждается
Первая важная проверка — масштабируемость. Если идея правильная, потери при обучении должны снижаться с ростом модели и данных. Так и происходит.
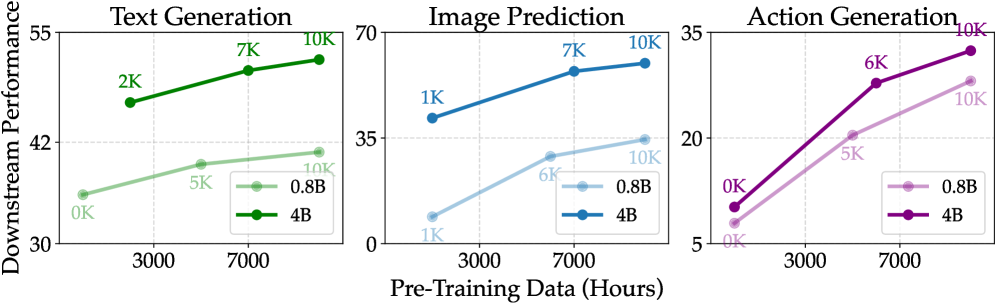
Чем больше модель и данных, тем лучше работают декодеры: улучшаются текст, предсказание изображений и действия робота.
Но гораздо интереснее вторая проверка: помогает ли более сильная модель мира в прикладных задачах? Здесь ответ тоже положительный. По мере роста предобучения улучшаются все три считывания — текст, изображение и действия.
Это, пожалуй, самый важный результат статьи. Он показывает, что авторы не просто обучили очередную видеомодель, а действительно получили общее внутреннее представление, которое переносится между задачами.
Особенно интересно, что выигрыш есть и в робототехнике, хотя на этапе предобучения модель не видела размеченных действий. Для области, где данных с реальных роботов всегда мало и они дорогие, это очень сильный сигнал: возможно, часть навыков можно выращивать из обычного видео, если модель умеет понимать переходы состояний.
Текст: Orca лучше понимает изменения, причинность и движение
В текстовых тестах Orca проверяли на четырёх бенчмарках, связанных с пониманием видео, временной динамикой, пространственными отношениями и причинными вопросами.
Результат у Orca-4B сильный: в среднем она обходит сопоставимые по размеру модели и некоторые специализированные подходы. Особенно заметен прирост в задачах, где важно не просто распознать объект, а понять как сцена меняется во времени.
Авторы отдельно разбили качество по четырём большим категориям:
Там Orca особенно хорошо выглядит именно в переходах состояний и динамике. Это логично: если ты учился по видео и событиям, то должен лучше схватывать, что из чего следует.
Важно, что здесь не заявляется магия уровня “всё понимает лучше всех”. В пространственных задачах отрыв уже небольшой. Но общая картина ясна: ставка на предсказание следующего состояния действительно помогает в тех вопросах, где нужно мыслить во времени, а не просто смотреть на один кадр.
Изображения: не “красивее”, а физичнее
Часть про изображения, пожалуй, самая необычная. Авторы не хотят соревноваться в художественной генерации. Их интересует другое: может ли скрытое состояние Orca помочь предсказать, как изменится реальная сцена после действия.
Для этого они сделали собственный бенчмарк реальных взаимодействий. На вход подаются исходное изображение и инструкция. На выходе нужно получить картинку результата. Причём оценивается не красота, а соответствие действию, сохранение сцены и физическая правдоподобность.
Здесь Orca-4B показывает лучший средний результат среди сравниваемых моделей. По описанию и примерам видно, где именно преимущество: меньше “телепортации” объектов, меньше лишних предметов из воздуха, лучше сохраняется поза робота, связи контакта и логика сцены.

Сравнение предсказания изображений в реальных сценах: Orca лучше сохраняет структуру сцены, объекты и правдоподобные изменения после действия.
Это тонкий, но важный сдвиг. Обычно генеративные модели изображений очень хороши в визуальном правдоподобии, но могут быть плохи в причинной правдоподобности. То есть картинка красивая, но непонятно, как мир до такого состояния дошёл. Orca, судя по результатам, лучше держится за причинную нить.
Роботы: самая сильная часть статьи
Самая живая и убедительная часть работы — эксперименты на реальном двухруком роботе. Пять задач. Два жёстких режима обобщения: новые окружения и новые объекты. Для дообучения всего по 200 траекторий на задачу. Это мало.
И вот здесь Orca показывает, что идея модели мира может быть полезна не только в тестах на понимание, но и в физическом действии. В среднем она заметно обходит Qwen3.5 с тем же модулем действий и оказывается сопоставима, а местами лучше сильной специализированной робототехнической модели π0.5, которая предобучалась на больших робототехнических данных.
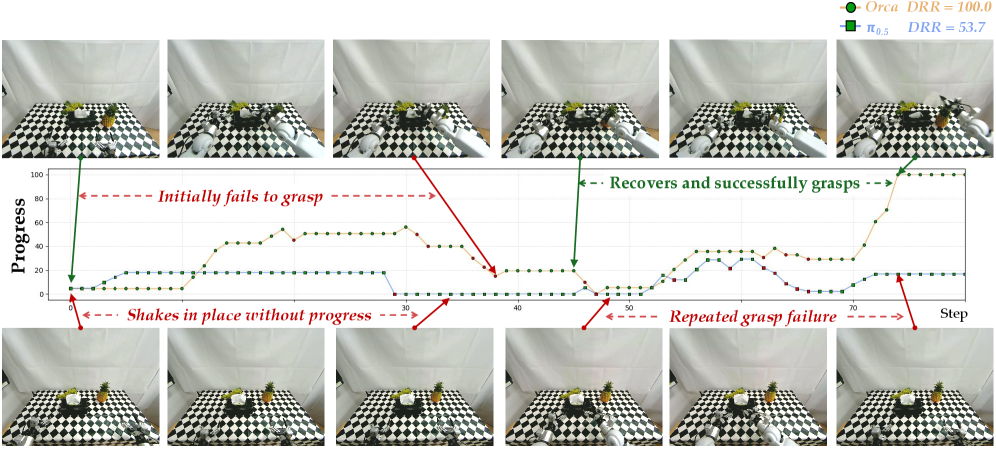
Orca лучше восстанавливается после неудачных захватов: робот не застывает, а пробует ещё раз и продвигается по задаче.
Самое интересное тут даже не сухая успешность. Авторы смотрят на промежуточный прогресс и способность восстанавливаться после ошибок. И Orca выглядит сильнее именно как система, которая “понимает, что пошло не так” и пытается вернуться в рабочее состояние. Например, если робот неудачно схватил ложку, Orca чаще делает повторные осмысленные попытки, а не зависает.
Это очень хороший признак. В реальном мире провалы случаются постоянно. Робот, который просто следует шаблону, ломается от первого отклонения. Робот, у которого есть хотя бы грубая модель состояния мира, может заметить, что цель не достигнута, и скорректироваться.
Что в работе особенно ценно
У статьи есть несколько по-настоящему сильных сторон.
Во-первых, правильная постановка задачи. Переход от “следующего токена” к “следующему состоянию” — не просто маркетинг. Это полезная рамка, если мы хотим систем, которые понимают мир, а не только имитируют ответы.
Во-вторых, проверка одной идеи сразу в трёх каналах: текст, изображения, действия. Это делает работу гораздо убедительнее.
В-третьих, хорошая методическая честность. Авторы замораживают ядро и обучают только лёгкие выходы. Это снижает риск, что успех объясняется просто большим числом обучаемых параметров в конкретной задаче.
В-четвёртых, акцент на реальном мире. Не на синтетике, не на красивой генерации, а на сценах, где есть объекты, контакт, ошибка, повторная попытка.
Где слабые места и почему до “универсального мира” ещё далеко
При всей силе идеи, статья честно показывает и свои ограничения.
Первое: Orca пока в основном живёт в зрении и языке. А реальный мир — это ещё звук, тактильность, сила, температура, собственное состояние тела. Без этого модель мира остаётся неполной.
Второе: модель учится предсказывать состояние не напрямую, а в пространстве уже готового визуального кодировщика. Это удобно инженерно, но значит, что “мир” частично наследует ограничения чужого визуального пространства.
Третье: масштаб пока умеренный — 0.8B и 4B. Для настолько амбициозной идеи этого явно мало. Авторы сами пишут, что между текстом, изображением и действием у небольшой модели возникает компромисс.
Четвёртое: горизонт предсказания короткий. Orca хорошо учится локальным переходам состояния, но это ещё не модель длительных процессов на часы или дни.
И наконец, часть оценок, особенно в изображениях, всё ещё довольно сырая. Собственный бенчмарк — это хорошо, но его ещё нужно обкатать сообществом.
Вывод
Orca — это не “ещё одна LLM с видео”. И не просто очередная робототехническая модель. Это попытка переопределить сам объект обучения: вместо слов, кадров и действий — состояния мира и их переходы.
Получилось не всё. До общей модели мира здесь огромная дистанция. Но работа уже даёт важный практический вывод: если учить систему на естественной динамике видео, осмысленных событиях и языковых условиях, можно получить внутреннее представление, которое полезно сразу для нескольких разных задач.
Главная ценность Orca в том, что она возвращает разговор об ИИ к более фундаментальному вопросу: понимает ли модель, как мир меняется. И вот на этот вопрос статья впервые даёт не философский, а вполне инженерный ответ.
Пока осторожный. Но уже очень интересный.
ИИ-обзоры простыми словами
Каждый день читаем свежие статьи по ИИ и пересказываем главное человеческим языком — без хайпа и воды. Если хотите понимать, куда движутся ИИ-агенты раньше остальных, — подписывайтесь.
Новые обзоры — каждый день
В Telegram